Natural Language Processing
Chenghao Ding, 06 May 2021
Natural Language Processing
- Questions 1: Identify the spam emails from hams?
- Questions 2: Identify the disaster tweets from 10,000 of tweets?
In this project, several datasets are going to be used to show how different machine learning model can be applied to various applications in NLP, such as text classification and sentiment analysis.
1. Loading Data and Exploratory Data Analysis

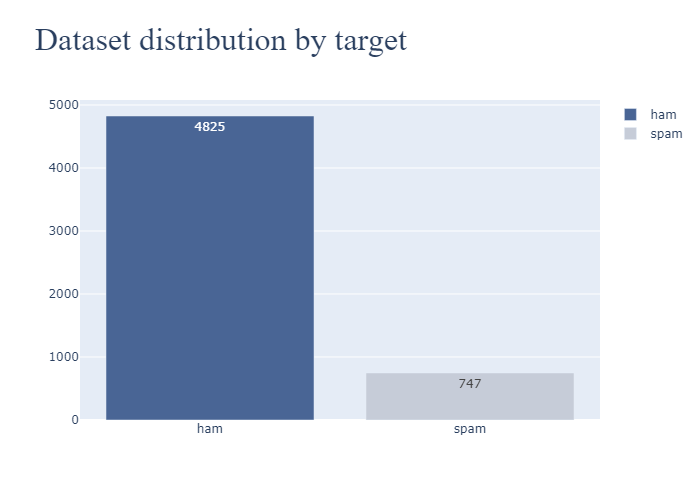
As we can see, the classes are imbalanced, so we can consider using some kind of resampling.
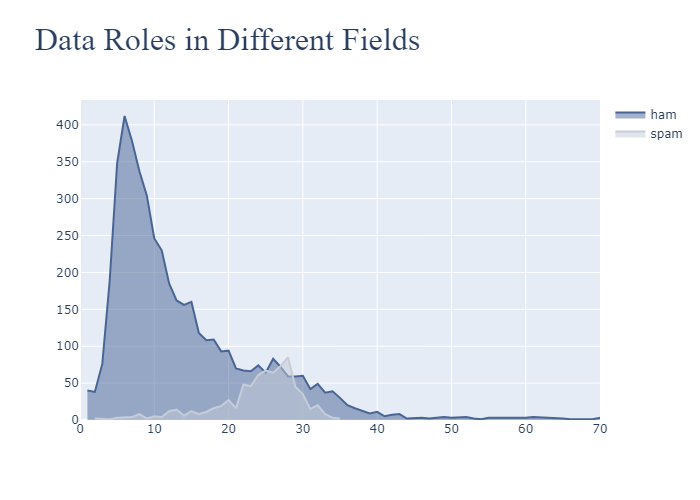
As we can see, the ham message length tend to be lower than spam message length.
2. Data Pre-processing
Before we feed texts into our machine learning models, we need to clean the corpus, and remove stop words, as well as stemming or lematization. After that, encode texts into vectors.
2.1 Cleaning the corpus
Make text lowercase, remove text in square brackets,remove links,remove punctuation and remove words containing numbers.
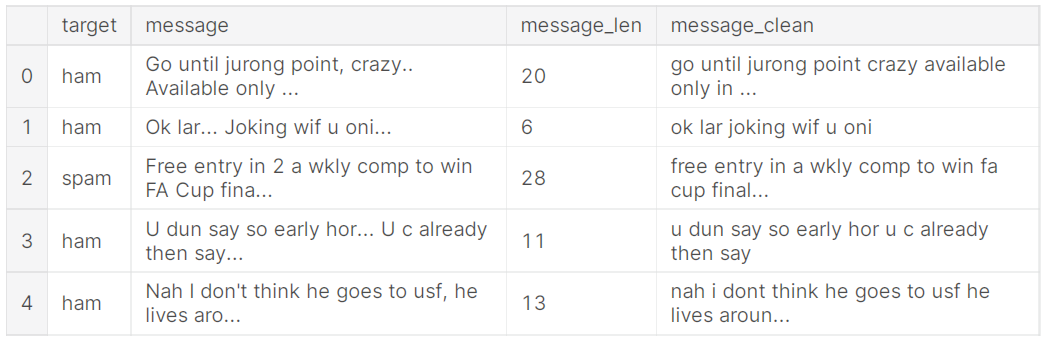
Remove Stopwords
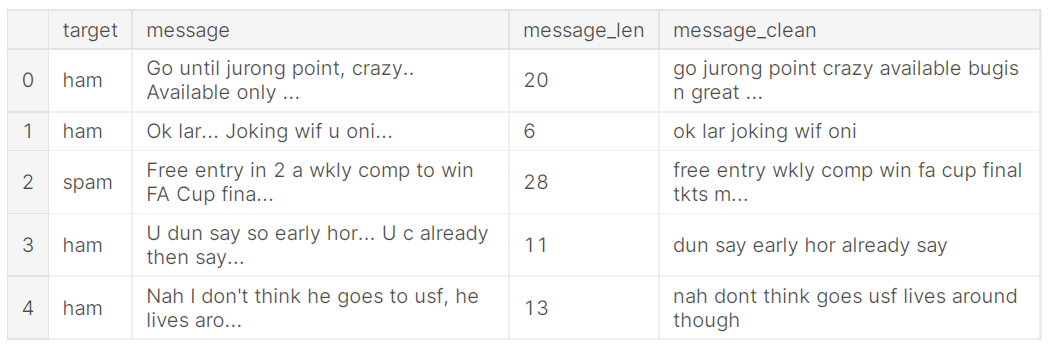
Stopwords are commonly used words in English which have no contextual meaning in an sentence. So therefore we remove them before classification. The figure below shows the cleaned texts after stopwords are removed.
2.2 Stemming/Lemmatization
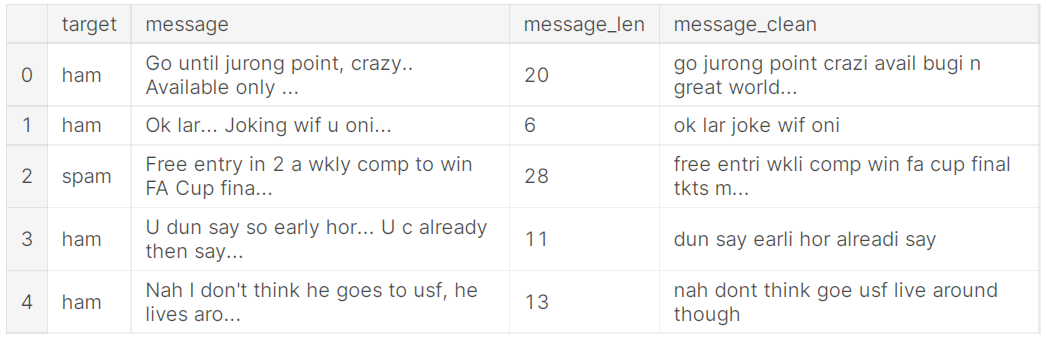
Stemming usually refers to a process that chops off the ends of words in the hope of achieving goal correctly most of the time and often includes the removal of derivational affixes.
Lemmatization usually refers to doing things properly with the use of a vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only and to return the base and dictionary form of a word.
2.3 Target encoding
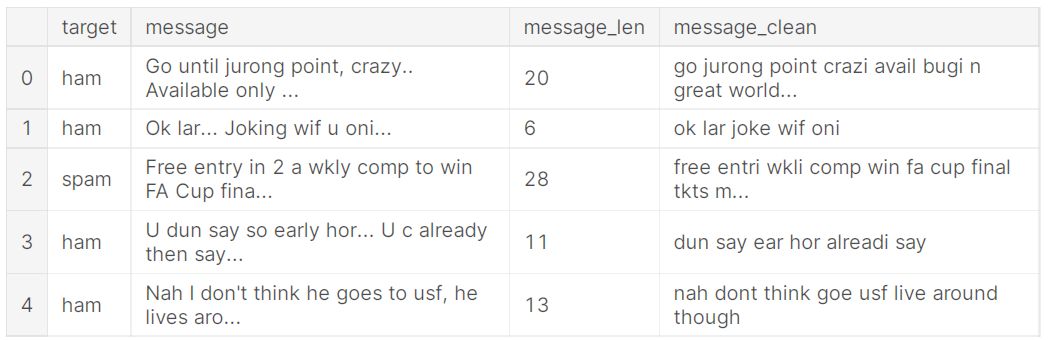
Now, the corpus have been cleaned. The figure below shows the cleaned sentences.
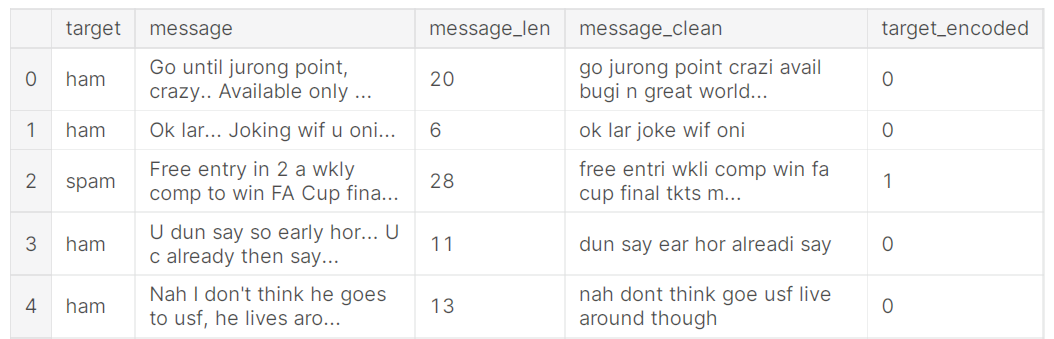
Now, we need to label the ham as 0, but spam as 1.
3. Tokens visualization (Word Cloud) and Vectorization
Top Words for HAM emails
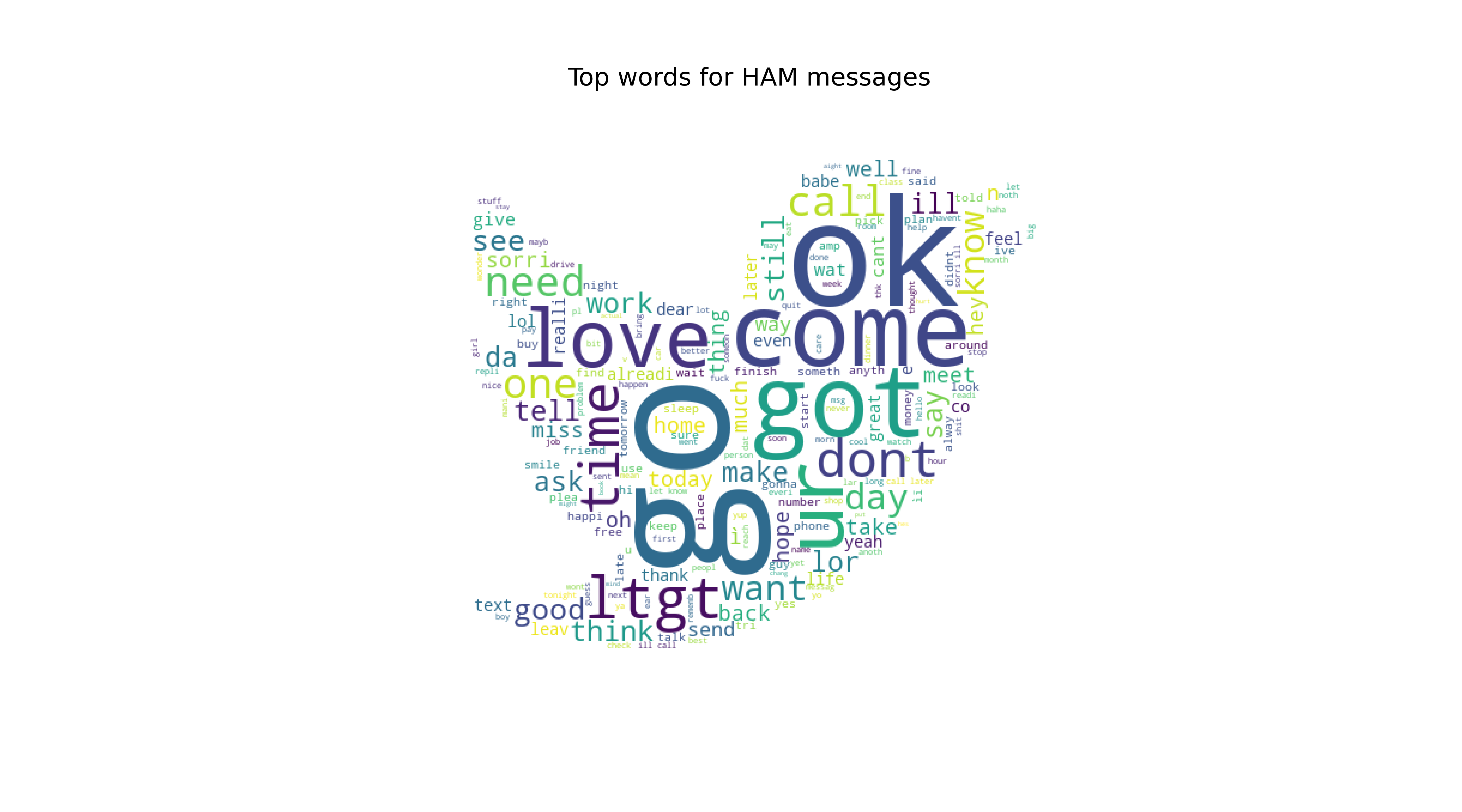
Top Words for SPAM emails

We will first use SciKit Learn’s CountVectorizer. This model will convert a collection of text documents to a matrix of token counts. Tunning CountVectorizer: CountVectorizer has a few parameters such as “stop_words”, ngram_range, “min_df, max_df”, “max_features”.
Word Embeddings: GloVe
We can derive semantic relationships between words from the co-occurrence matrix. Now we will load embedding vectors of those words that appear in the Glove dictionary. Others will be initialized to 0.
4. Build Model
4.1 Naive Bayes
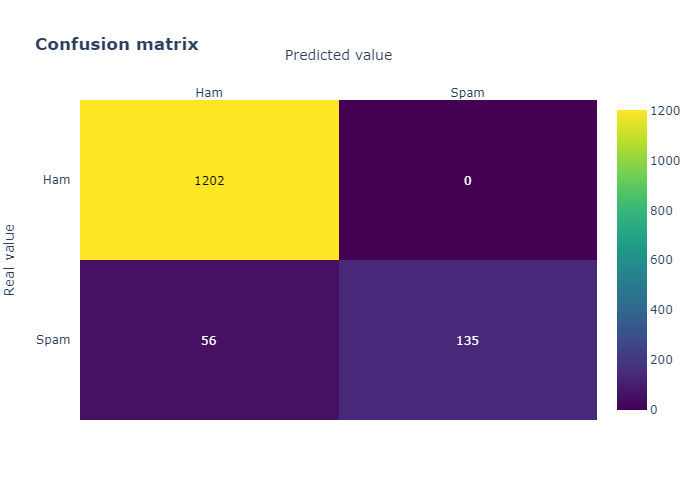
Accuracy = 0.96.
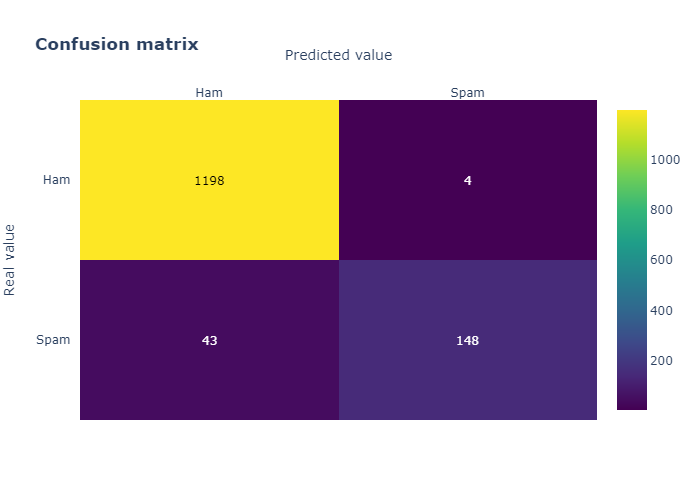
4.2 XGBoost
Train Accuracy = 0.98. Test Accuracy = 0.96.
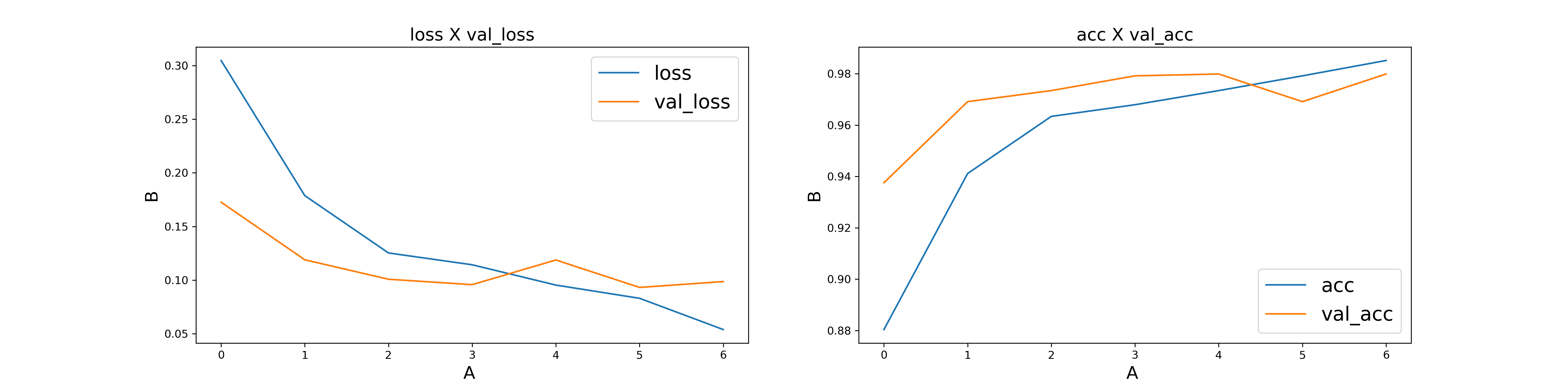
4.3. LSTM Model
After epoch 3, the loss of validation didn’t imporved. There’s overfit problem.
5. Disaster Tweets

5.1 Data Pre-Processing
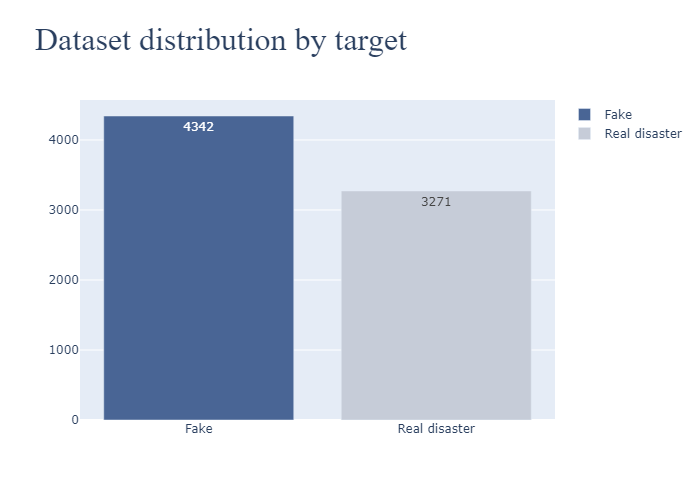
5.2 Word Cloud
Top Words for Real Disaster Tweets

Top Words for Fake Disaster Tweets
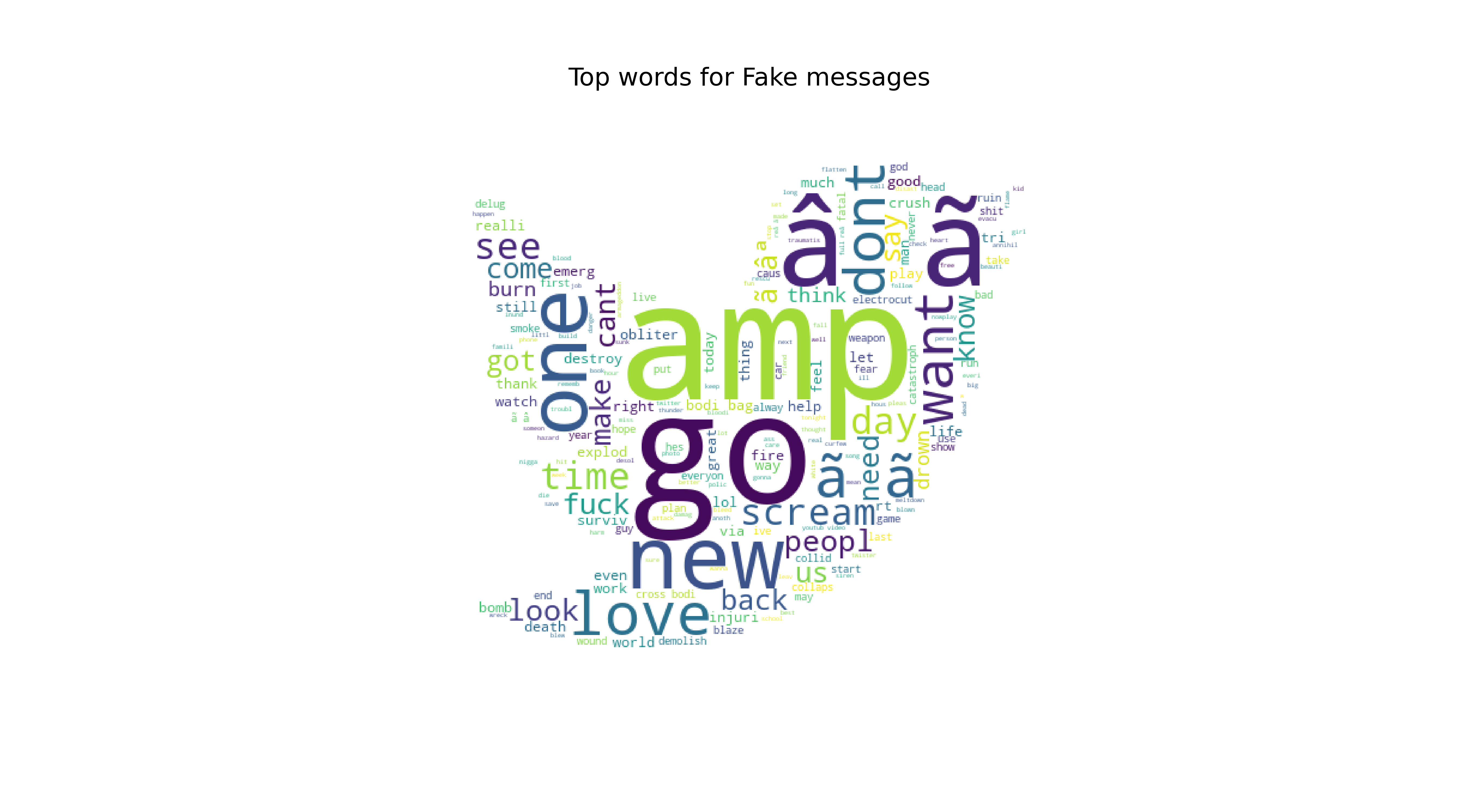
5.3 GloVe-LSTM Model
First, we use the embedding layer to map the words to their GloVe vectors, and then those vectors are input to the LSTM layers followed by a Dense layer with ‘sigmoid’ activation.
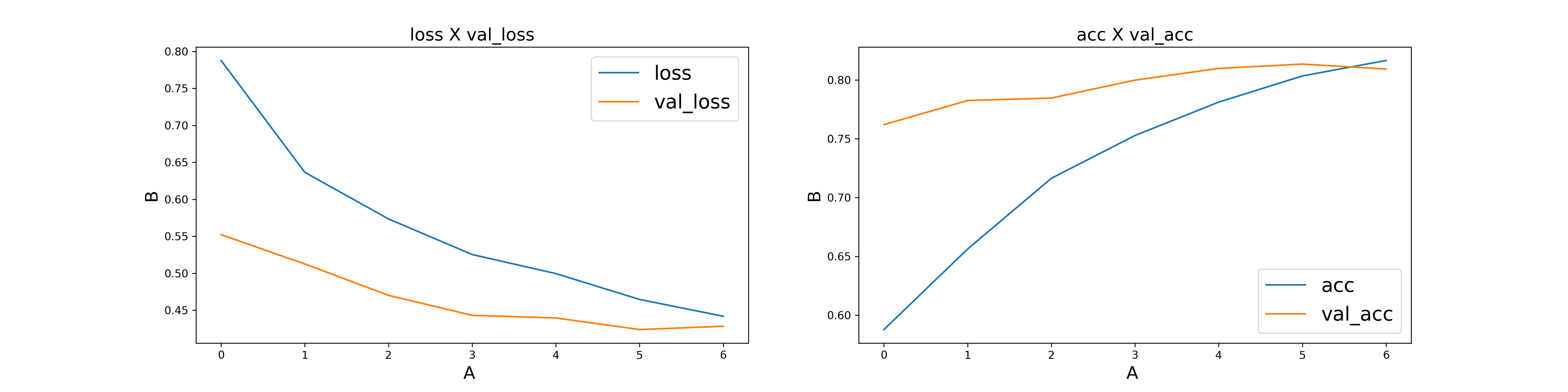
Accuracy: 0.81